Comma-separated values (CSV)
I am working at the IT-Department of Universitätsklinikum Erlangen (University Hospital Erlangen) and this week I created a CSV file for a other project. The aim of this project is to migrate clinical findings into a new system. The clinical findings in the old system don’t have identifiers like a patient-id or a case number but some demographic data (name, surname, birthdate, zip code, …). The project manager and his developer who are responsible for the migration contacted me and asked for demographic data of our patients to implement a heuristic to assign the clinical findings to the correct patients.
In computing, a comma-separated values (CSV) file stores tabular data (numbers and text) in plain text. Each line of the file is a data record. Each record consists of one or more fields, separated by commas. The use of the comma as a field separator is the source of the name for this file format. – Wikipedia
The extraction of the desired data was easy, but they asked if I could create an CSV file for them. They told me that they send me an example file as an orientation. They used carriage return linefeed (<CR><LF>) as line separators and semicolon as data field separator and the file has a header line.
surname;name;birth-date;zip;phone-number doe;john;01.01.2016;55555;555-123-1235543doe;jane;02.02.1980;55555;555-321-42332
I created the CSV file similar to the example file but due to my bad experiences in the past with CSV I counted the semicolons after the export. Of course there have been more then I expected. There should be 4*[number of lines] semicolons but there have been a lot more. After a short search I found that the most of the supernumerary semicolons are from the telephone field. In the telephone-number field are often multiple numbers divided by semicolons. I think there is only one field for a telephone number in the gui mask of the patient registration software. The resulting CSV file was kind of broken:
surname;name;birth-date;zip;phone-number
doe;john;01.01.2016;55555;555-123-1235543; 123-334534
doe;jane;02.02.1980;55555;555-321-42332
The developer told me that i can wrap the values in double quotes (“). No Problem:
surname;name;birth-date;zip;phone-number "doe";"john";"01.01.2016";"55555";"555-123-1235543; 123-334534" "doe";"jane";"02.02.1980";"55555";"555-321-42332; 321-22222"
When I asked how I should escape double quotes within the data he told me that I don’t have to escape them because he reads from the first double quote until he finds a double quote followed by a semicolon. But this will not work in the following example:
surname;name;birth-date;zip;phone-number
"doe";"john";"01.01.2016";"55555";"555-123-1235543"; 123-334534"
"doe";"jane";"02.02.1980";"55555";"555-321-42332; 321-22222"
Luckily this constellation appeared not in the exported data so I created the CSV file and hope that they can import it.
This experience is very similar to all the other CSV file creation tasks I have done at my work. Every time I create a CSV file there are some problems and I never exported a CSV file which could be read immediately by the other side.
Beside these syntax problems there are also semantic problems. If there is a telephone number in a data field this data has to be treated as string because in telephone numbers leading zeros are important, if you treat these values as numeric data you can loose leading zeros for example. This can happen if you open a CSV file with a spreadsheet program change something and save it.
Alternatives
Due to all this problems when dealing with CSV files I’d like to find out if there are appropriate alternative formats which are easier to handle without too much overhead in terms of file size. There are plenty of formats for data exchange but I decided to compare only to XML and JSON as two widely used formats. Additionally I decided to compare CSV file size with BSON which is not so common but a binary format (I think it is mostly used in connection with MongoDB).
Aproach
I wrote a small python script which creates a CSV file based on example data. I also created some other files with different formats based on the same data and compared the filesize with the CSV file. I compared the size of the plain files and of the gziped files. You can find the script and the generated output files I used for the following comparison at https://github.com/MartinEnders/csv-alternatives-comparison.
I used a list of German words from https://sourceforge.net/projects/germandict/files/ with 1.6 Million words as data for my test. The script generates a CSV file with seven columns and 256000 rows first and then it generates files with the following formats: CSV, JSON, XML and BSON. In the alternative formats I separated the header from the body to make the output a little more structured. So there is always a header section which includes the data from the first line in the CSV file and a body section which includes the rest of the data. You can see the idea of the structure in the screenshots in table below.
There is also an version of the JSON and the XML file where the data is intended for better human readability. These both formats are listed in the table as JSON or XML ‘with indent’.
Result
As you can see in the following diagram the most compact format plain and gzipped is the CSV format followed by JSON, XML and BSON. The XML and JSON formats with indent are the worst in terms of file size (but the best human readable formats IMHO). If you look at the gzipped file size there is not much difference between the single formats except for the BSON file which is approximately 60% bigger then the biggest of the other formats which is JSON with indent.

File size in bytes
The following diagram shows the file size ratio compared to the CSV format. Here we can see that the overhead of JSON and XML is 23% and 26% compared to CSV. The plain formats with indent are upto more then twice as big (JSON with indent) as the CSV file.
When the files are gzipped JSON is 4% and XML 6% bigger than the gzipped CSV file. The files with indent are 13% bigger for JSON and 10% bigger for XML as CSV.
Plain BSON format is 55% bigger and gzipped 74% bigger then the corresponding CSV files.
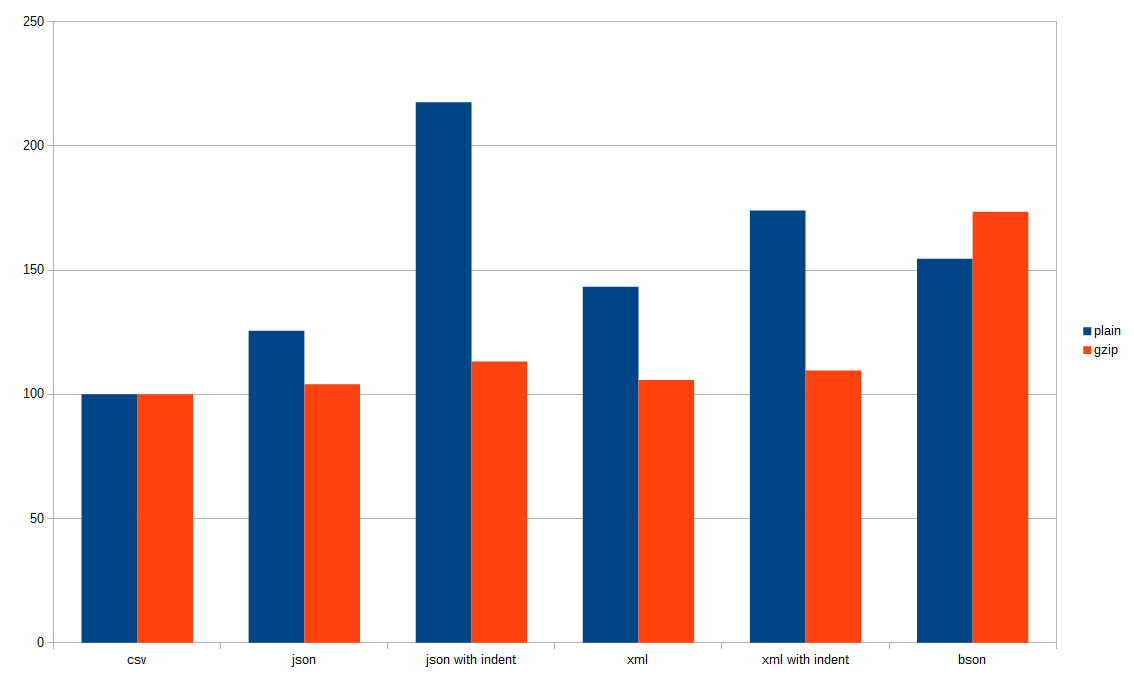
File size ratio compared to CSV
| format | file size | gzip file size | |||||
| bytes | MB | % | bytes | MB | % | ||
| CSV | 28376745 | 28 | 100 | 5884444 | 5.7 | 100 |  |
| JSON | 35635585 | 34 | 126 | 6126003 | 5.9 | 104 |  |
| JSON with indent | 61747561 | 59 | 218 | 6665296 | 6.4 | 113 |  |
| XML | 40664824 | 39 | 143 | 6226691 | 6.0 | 106 | 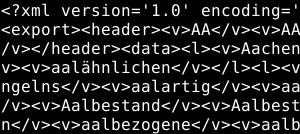 |
| XML with indent | 49368821 | 48 | 174 | 6449187 | 6.2 | 110 | 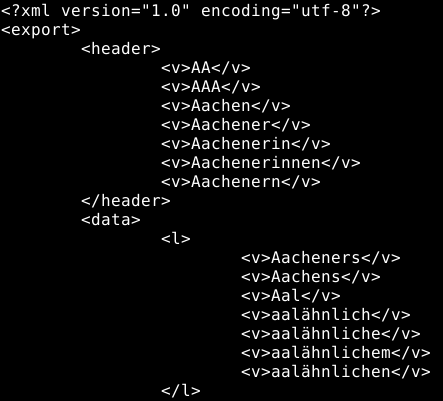 |
| BSON | 43881651 | 42 | 155 | 10213018 | 9.8 | 174 |  |
Conclusion
Due to the problems I already had with CSV I would prefer JSON or XML as data exchange format over CSV in the future in terms of usability. The JSON file is 26% and the XML file 39% bigger then the CSV file if you use plain JSON or XML without any indention. This could be a lot if you export really huge amounts of data but if you do so you don’t want to risk that there are format problems when you try to import your data again.
If file size or bandwidth matters I would choose JSON without indention and compress it. If file size or bandwidth doesn’t play such a big role I would use JSON or XML with indention and compress it if needed.
Other resources
- There is an iformational rft from the ietf which “documents the format that seems to be followed by most implementations” – https://www.ietf.org/rfc/rfc4180.txt
- The wikipedia article about csv mentioned above https://en.wikipedia.org/wiki/Comma-separated_values
- Website with the BSON specification: http://bsonspec.org/
Raised flower bed – 2017-01-29

Raised flower bed – 2017-01-29